





标题还没想好。
吐槽:弄个这玩意我是真的折磨住了。以后我写文档一定写的通俗易懂。然而。。我并不喜欢傻瓜式教学,而是喜欢启发式教学,但尽量把细节交代清楚。
官方文档:
如何用grafana以InfluxQL连接Influxdb v2
https://docs.influxdata.com/influxdb/v2.0/tools/grafana/?t=InfluxQL
在InfluxDB v2中配置v1映射
xxx
View and create InfluxDB v1 authorizations
在命令行中输入以下命令来建立v1授权账号。
(把这串id和用户名Mofeng、组织名Organization 换成你自己的)
influx v1 auth create \
--read-bucket 7083362765abbcde \
--write-bucket 7083362765abbcde \
--username Mofeng
若提示 must specify org ID or org name 或 401 Unauthorized,则需要额外提供org和token参数(记得改为你自己的)。


--org Organization
--token BU1abcdCeN0gbsdHMY7Ch7bj4Td1_MJoEDtDBBMCLWApj4mq6nHM87EaSHt-aHXjxEovUV1NYnYw3jM97KRpKQ==
如果是用docker部署的InfluxDB,可以通过docker exec -it influxdb1234(容器名) /bin/bash 来进入容器的命令行界面,再输入授权指令。
提交指令后,若没有问题,会提示你输入密码。(有问题我也不知道你的具体情况,尝试搜索解决吧)

输入完成后,即可看到结果。
View and create InfluxDB DBRP mappings
可以使用如下命令来查看现有的DBRP mappings
influx v1 dbrp list --org Mofeng --token BU1zawZCeNxxxxxxxx

可以看到默认情况下没有映射。
接下来,我们使用 influx v1 dbrp create 指令来创建一个新的映射。
参数解释:
--db:database name 要映射至v1的数据库名。
--rp:retention policy name 要映射至 v1 数据保留策略的名称(根据后续推断,这里作用相当于一级目录,位于bucket和measurement之间)
--bucket-id:要映射的v2 bucket的id
(可选)--default :flag to set the provided retention policy as the default retention policy for the database
(我没看懂default具体会对保留策略造成什么影响,哪里provided了?default的是什么?)
(推测:若加入--default参数,则--rp会被指定为default。通过后续查询的体验来看,建议加上--default参数)
上述参数中,db和rp只需要我们提供一个名称即可。但需要记住db和rp的名称,后续grafana连接时需要用到。
influx v1 dbrp create \
--db screeps \
--rp example-rp \
--bucket-id abcdefgX001 \
--default若提示 must specify org ID or org name 或 401 Unauthorized,则需要提供org和token参数(与上节相同)

提交后,可以看到映射已被创建。(注:这里没有用default参数,若有人知道了实际影响还请告诉我)
在Grafana中以InfluxQL连接InfluxDB
接下来就好办多了。
在grafana中选择添加数据源-InfluxDB
上半部分仅需填入URL
下半部分仅需填入数据库名(即上节的--db参数)、用户名( --username 参数)、密码,http方法选择GET即可。
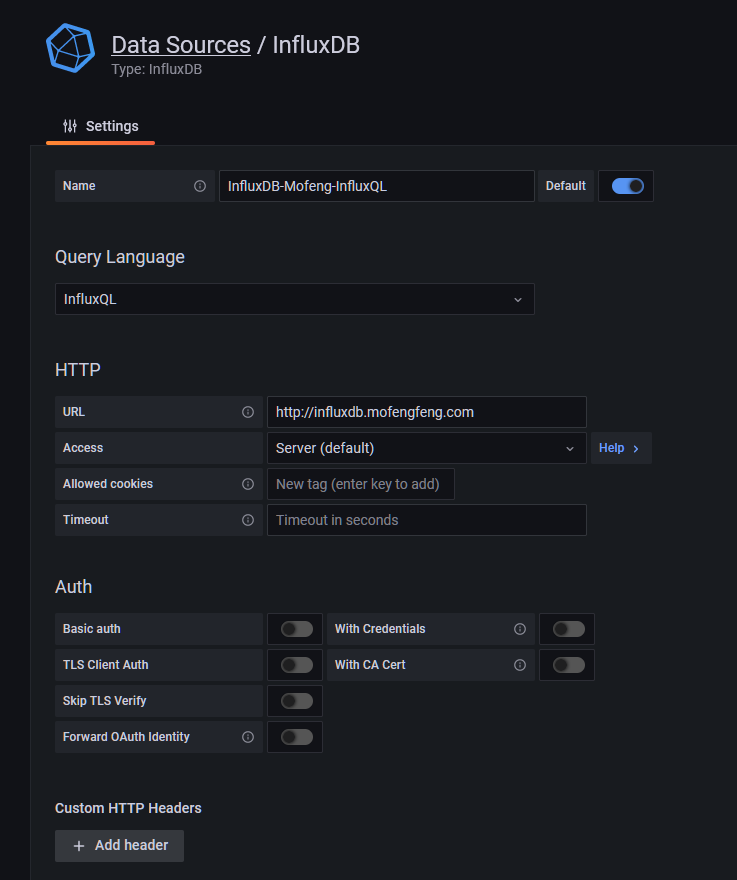
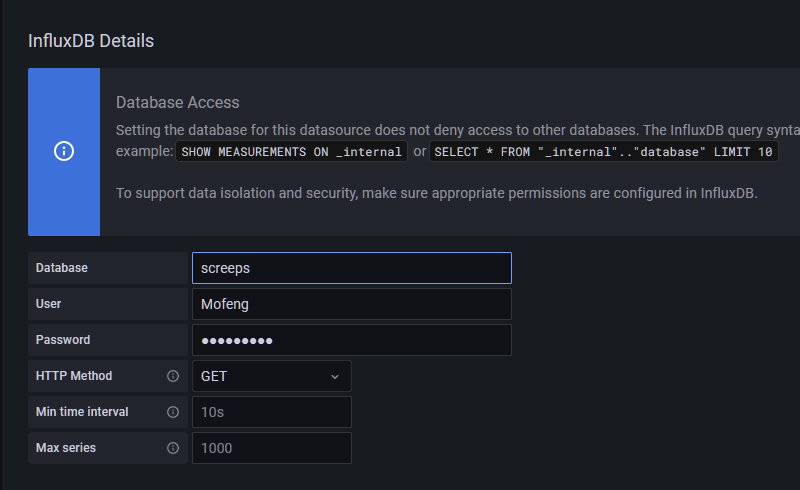
点击Save&Test进行测试,可以看到测试通过。
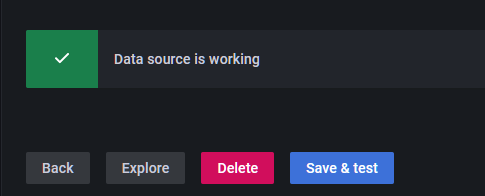
接下来,我们可以点击Explore进行测试。
我已向数据库中插入了少量数据以供测试。

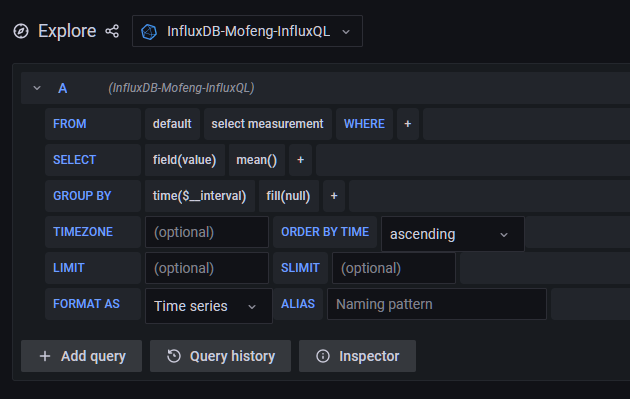
初始情况下,可以看到Explore是已被封装好的可交互界面,不像之前使用Flux查询一样只能自己输入Flux语句进行查询。
点击default,可以看到之前填入的--rp参数名。进行选择即可。若之前传入了--default参数,这里应该选择default即可
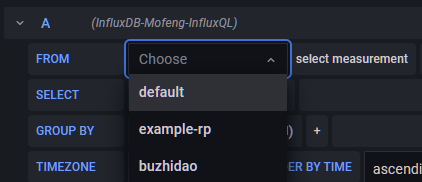
select measurement可以选择v2 bucket中存入的measurement。
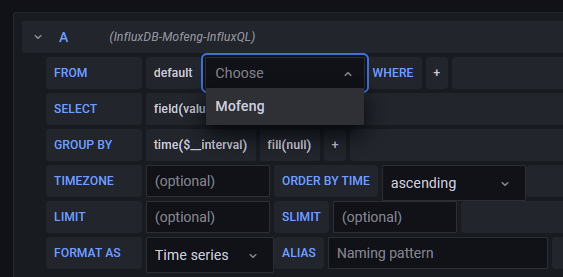
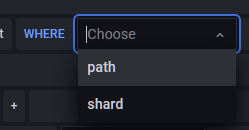
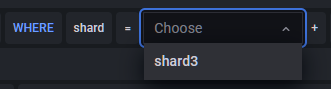
WHERE后的+可以对通过TAG进行筛选
SELECT中的field(value)可以选择你想查看的field字段
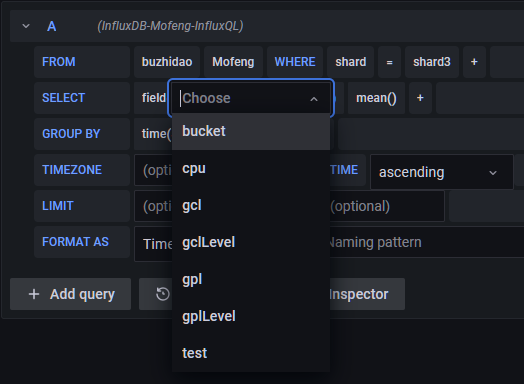
上述选择完成后,可以运行查询,下方即可显示数据的图表。
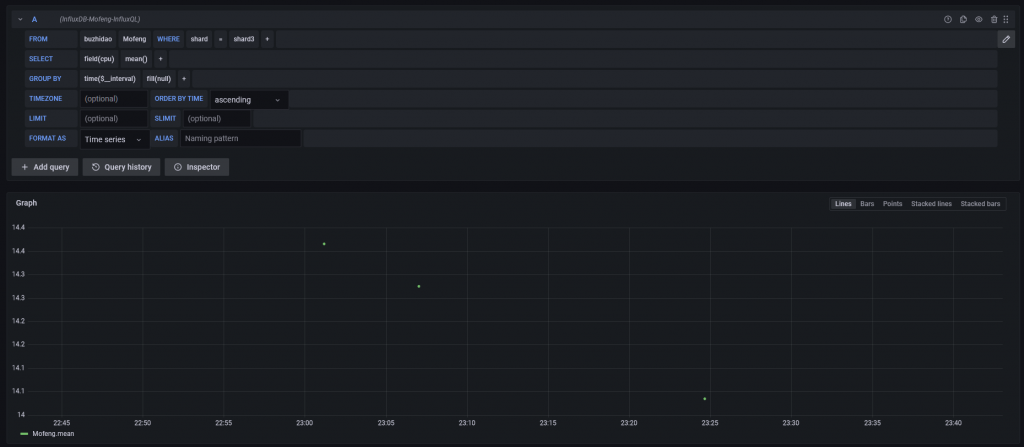
至此,在Grafana中使用可视化交互界面进行查询InfluxDB的目标已经完成,以后就在生成图表时就无需编写Flux语言,可以直接通过点击来筛选数据了!
Comments | NOTHING